KI-Chatbots und Phonebots für einen automatisierten Customer Service, der Ihre Kunden wirklich versteht
Bieten Sie Ihren Kunden rund um die Uhr erstklassigen Support – unterstützt von Generative AI.So sparen Sie Kosten, entlasten Ihre Mitarbeiter und machen Ihren Kundendienst zukunftsfähig.


























Die Herausforderung
83% der Kunden erwarten, dass der Kundenservice sofort erreichbar ist
Ein exzellenter Kundenservice ist wichtiger als ein niedriger Preis. Aktuelle Studien zeigen: Viele Kunden sind bereit, bei einem guten Service mehr zu bezahlen.
Lange Wartezeiten, überlastete Mitarbeiter und ungenügende Antworten auf Kundenfragen führen zu einer Abwanderung zu Wettbewerbern.
Dank Service-Automatisierung mithilfe von Conversational AI & Generative AI lassen sich diese Probleme lösen.
Die Lösung
Machen Sie mit Conversational AI Ihren Service zum Wettbewerbsvorteil
Bis zu 80 % automatisierte Kommunikation
Automatisieren Sie bis zu 80 % Ihrer Kundenanfragen mithilfe von Conversational AI und liefern Sie schnelle messbare ROI-Ergebnisse.
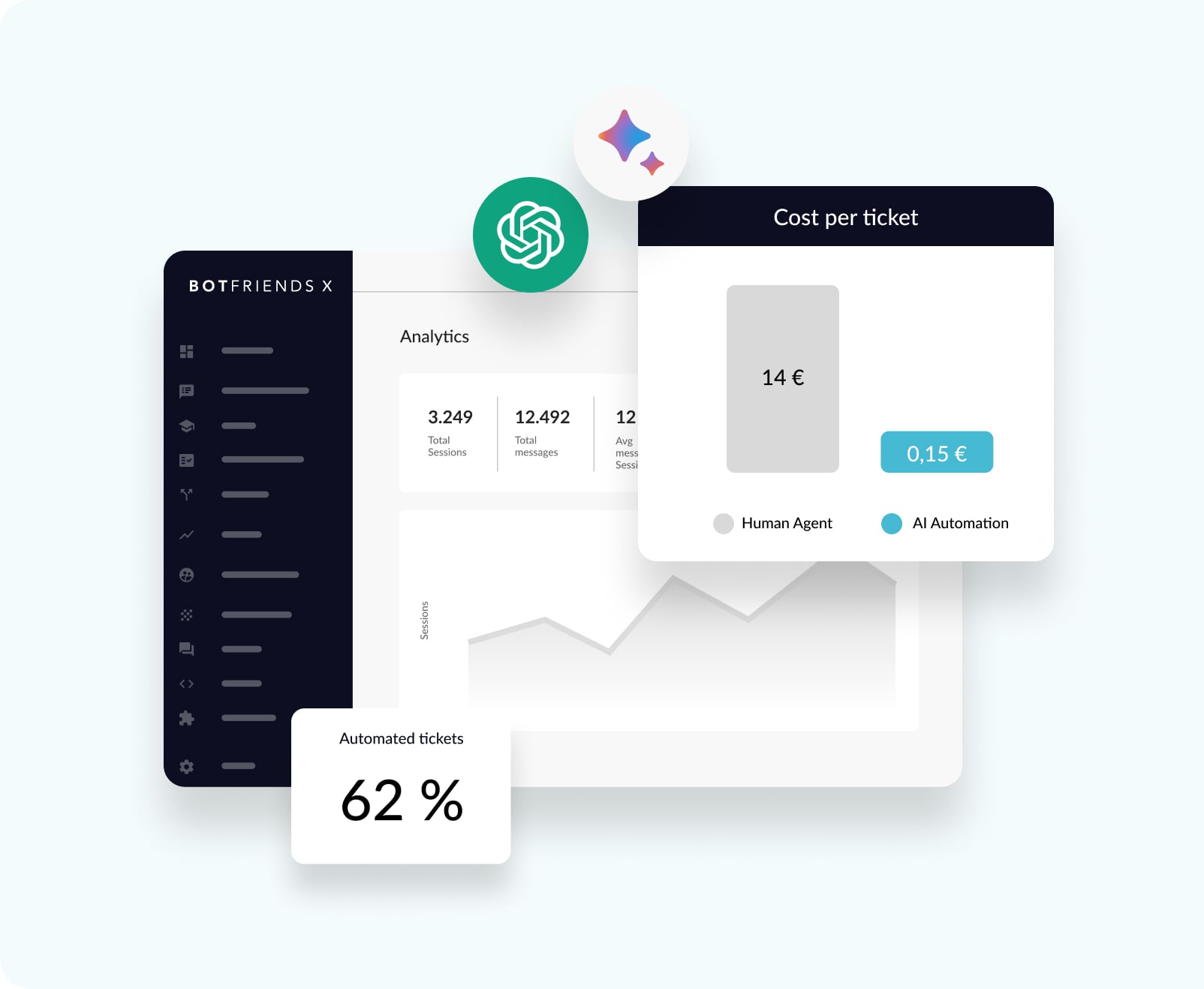
Kosten sparen & Effizienz steigern
Wickeln Sie wiederkehrende Anfragen via Chatbot ab. So haben Ihre Mitarbeiter Zeit für die wirklich wichtigen Anfragen. Senken Sie mit KI effektiv Ihre Cost per Interaction und Cost per Ticket.
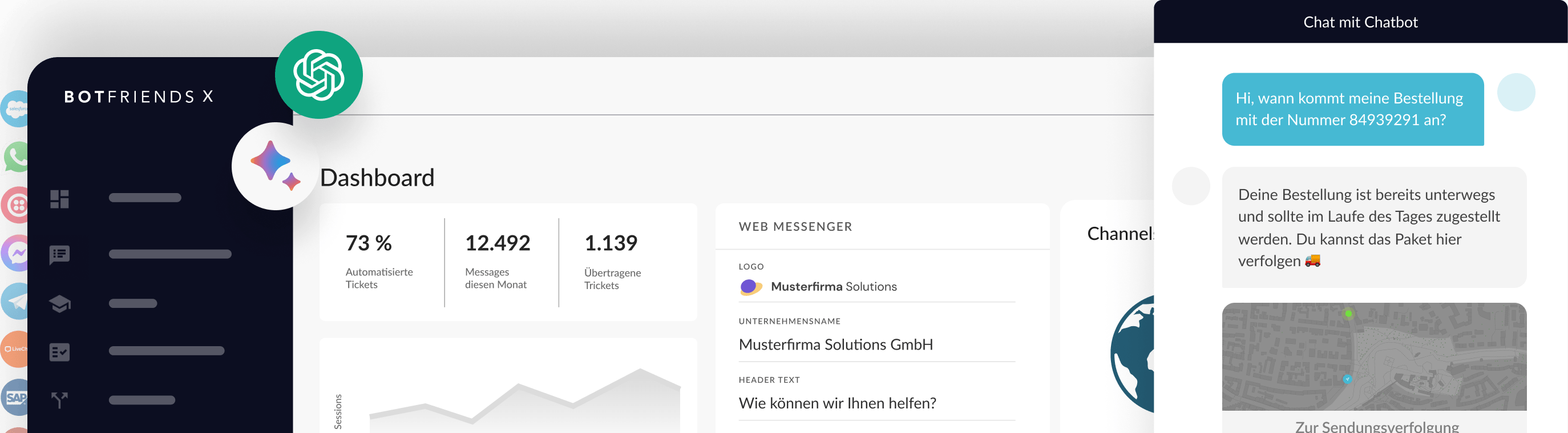
24/7 Verfügbarkeit auf allen Kanälen
Seien Sie auf genau den Service-Kanälen vertreten, die Ihre Kunden erwarten. Rund um die Uhr. In allen Sprachen.
100 % Service-Abdeckungauf allen Kanälen
Kundenservice ist heute nicht mehr linear. Seien Sie für Ihre Kunden auf allen Service Kanälen 24/7 erreichbar.
⌀ 65 % Automatisierungder Service-Anfragen
Unsere KI-Bots erkennen fast alle Anfragen – in jeder Sprache. Das sorgt für eine hohe Automatisierungsquote.
30.000 € Ersparnis
Selbst bei einfachen FAQ-Bots ist die jährliche Kosteneinsparung dank KI enorm. Verwenden Sie unseren ROI-Rechner für eine tiefere Analyse.
Chatbots für alle Branchen
Die BOTfriends X Plattform macht in zahlreichen Unternehmen aus den verschiedensten Branchen
Künstliche Intelligenz & Service Automatisierung zugänglich. Branchenvorlagen sorgen für schnelle Ergebnisse.
Customer Service
Automatisierung im Customer Service. Für ein herausragendes Kundenerlebnis und höhere Kundenzufriedenheit.
Tourismus
Egal ob Reiseberatung, den gesamten Buchungsprozess oder häufig gestellte Fragen: Smarte Bots für die Tourismusbranche.
Energie & Stadtwerke
Entlasten Sie Ihre Mitarbeiter und binden Sie Ihre Kunden mit schneller Hilfe, integrierten Prozessen und intelligenten Antworten.
Die leistungsstarke Conversational AI Plattform –Unterstützt von Generative AI
Erstellen Sie mit BOTfriends X einen virtuellen Kundendienstmitarbeiter, der rund um die Uhr erreichbar ist,
alle Sprachen beherrscht und genauso intelligent und nuanciert antwortet wie ein Mensch.
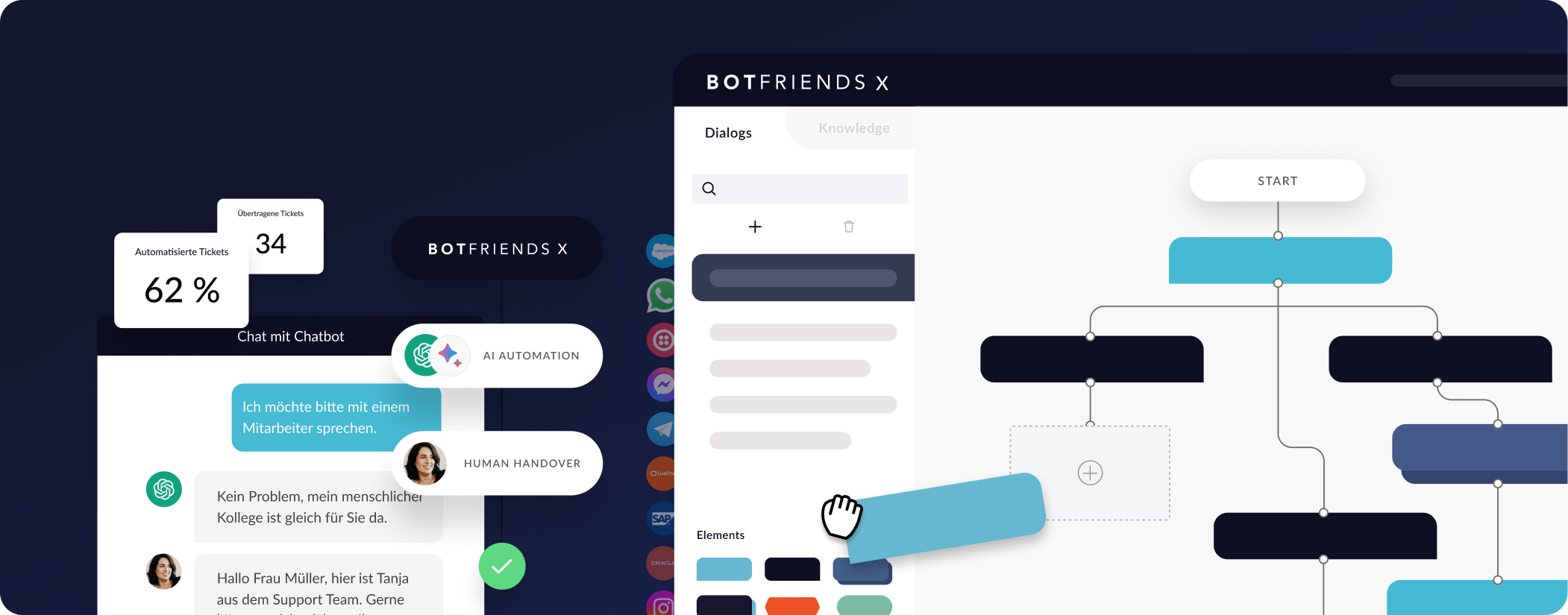
Kein Code
Erstellen und trainieren Sie auch ohne Entwicklungskenntnisse KI-Bots. Unsere No Code Lösung macht es möglich.
Human Handover
Hat ein Chatbot keine geeignete Antwort parat, kann er Ihre Nutzer per Live Chat an Ihre Mitarbeiter weiterleiten.
Mehrsprachigkeit
Bieten Sie einen multilingualen Support. Ihr Bot versteht und antwortet in mehr als 120 Sprachen.

Rollenmanagement
Arbeiten Sie im Team an Ihren Botprojekten und entscheiden Sie, wer worauf Zugriff haben soll.
Analytics
Mithilfe der Analyticsdaten lässt sich der Erfolg Ihrer Bot-Projekte überwachen und weiter optimieren.
Ihr Bot wächst mit
Eine neue API? Ein weiterer Kanal? Kein Problem – Sie können Ihr Bot Setup jederzeit erweitern und skalieren.
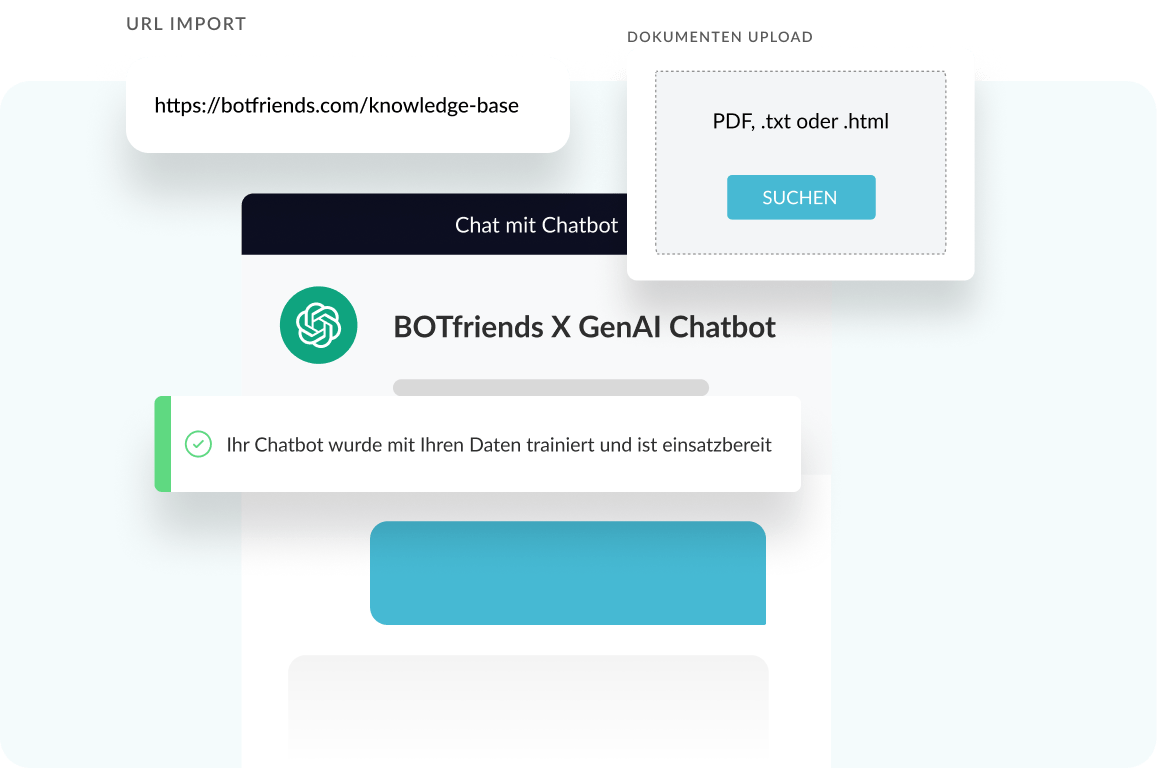
Von der Knowledge Base zumChatbot in nur wenigen Minuten
Importieren Sie Dokumente oder Website URLs in unsere Chatbot-Plattform. Der Chatbot lernt selbstständig auf Basis Ihrer Daten und ist in wenigen Minuten einsatzbereit.
So sparen Sie das zeitaufwändige initiale Training und das manuelle Hinzufügen von Fragen und Antworten. Generative AI nimmt Ihnen diese Arbeit ab!
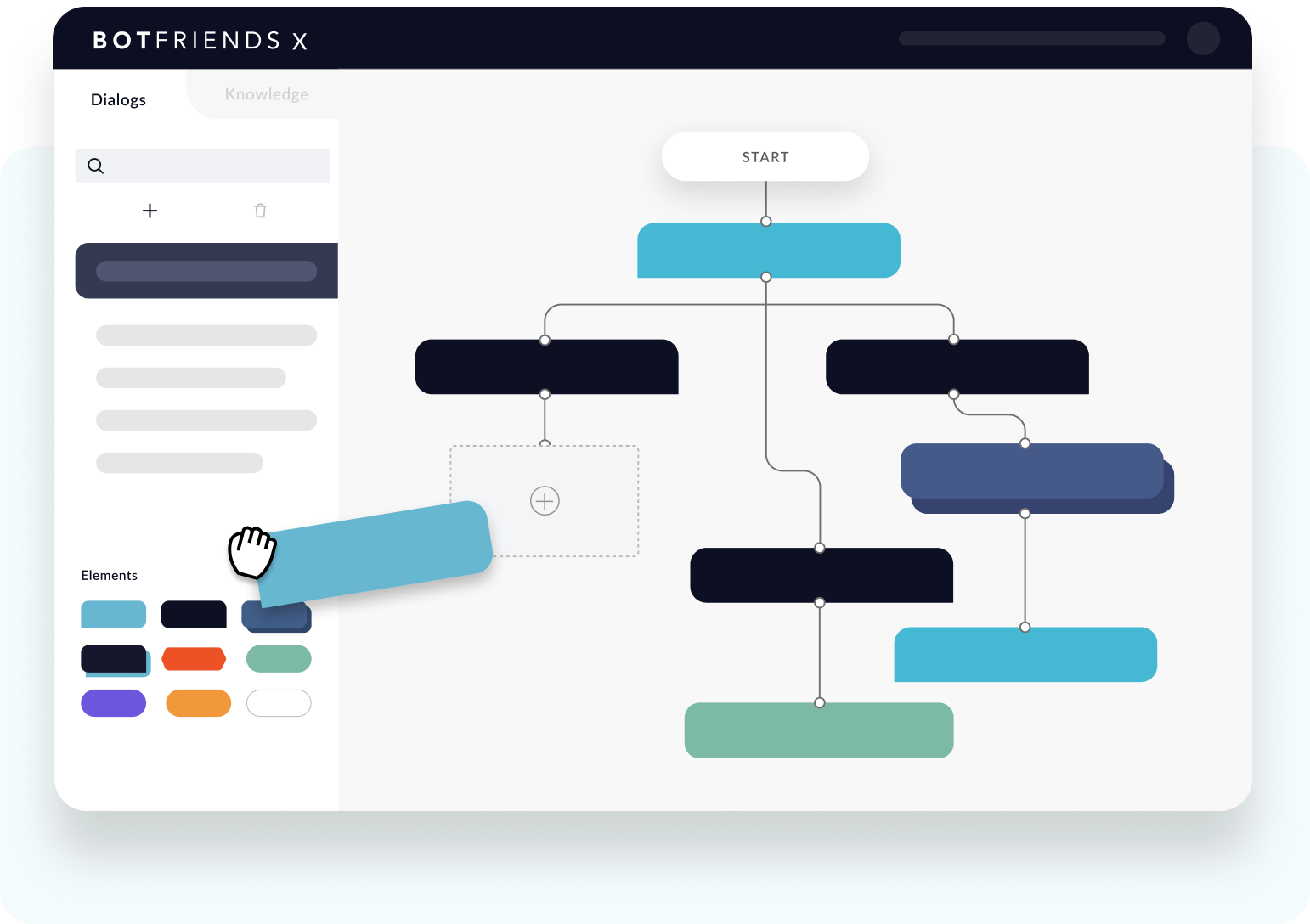
Erstellen Sie Bots so intuitiv undgraphisch wie nie zuvor
Vergessen Sie komplexe Programmiersprachen und stundenlange Schulungen. Erstellen Sie mit Dialogs Bots ganz einfach interaktiv per Drag and Drop.
Jeder Dialog, jede Antwort und jede Integration ist wie ein Baustein, den Sie nach Belieben anordnen können. Dies ermöglicht maximale Flexibilität und Kreativität beim Aufbau Ihrer Bots.
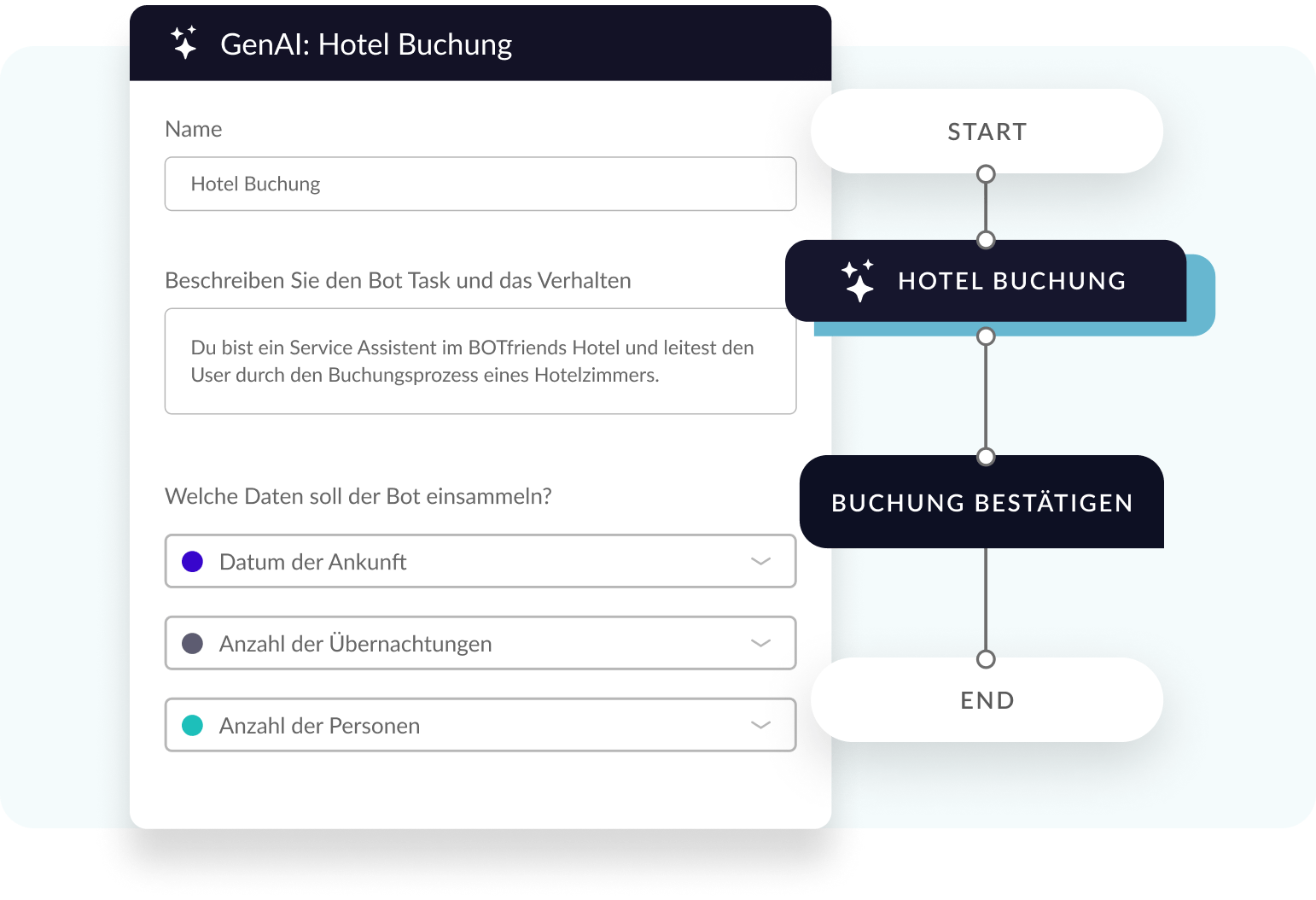
Komplexe Abläufe in Rekordgeschwindigkeit: GenAI Nodes
Bislang war das Erstellen komplexer Bot-Prozesse zeitaufwendig. Mit GenAI Nodes schreiben Sie einfach eine Aufgabenbeschreibung und definieren, welche Daten der Bot sammeln soll.
Die GenAI-Technologie kümmert sich um den Rest. Sie modelliert die benötigten Prozesse, berücksichtigt alle möglichen Szenarien und behandelt sogar komplizierte Edge Cases. Ein Prozess, der bisher Tage dauern konnte, wird jetzt in wenigen Minuten erledigt.
Nutzen Sie GenAI Nodes für vielfältige Anwendungen wie Terminbuchungen, Hotelreservierungen oder das Melden von Zählerständen.
Integrationen
Verbinden Sie BOTfriends X frei mit zahlreichen Integrationen, Diensten und Third Party Tools.
Dadurch automatisieren Sie Prozesse und haben mehr Zeit für die Dinge, die wirklich wichtig sind.
Datenschutzkonforme KI-Voice- und Chatbots für Ihr Unternehmen
Mithilfe der BOTfriends X Plattform werden monatlich eine hohe Anzahl an Konversationen über die gut trainierten KI-Assistenten abgewickelt. Damit das in Deutschland und der EU überhaupt möglich ist, unterliegen alle unsere Services den strengen Auflagen der DSGVO.
DSGVO-konform
Unsere Conversational AI Plattform ist ideal für den Einsatz in Deutschland und der Europäischen Union.
Auftragsverarbeitung
Gemäß des Datenschutzrechts erhalten Sie von uns einen Auftragsverarbeitungsvertrag (AVV).
Sicherer Login
Sicherer Zugriff auf Ihre Chatbot-Daten durch Login mit Two Factor Authentication.
Ihr Strategiegespräch mit KI-Experten
Möchten Sie erfahren, wie unsere innovativen Conversational AI Lösungen und Chatbots Ihre Kundenkommunikation revolutionieren können? Füllen Sie unser Kontaktformular aus und wir melden uns umgehend bei Ihnen zurück. Lassen Sie uns gemeinsam Ihre Ziele erreichen.

- Konkrete KI-Handlungsempfehlungen für Ihren Bereich
- Auskunft über erforderliche interne Ressourcen & Kosten
- Unverbindlich & Kompetent
- Einfache Integration in Ihre Systeme (z.B.: SAP)