
 AI Agent ROI Rechner
AI Agent ROI Rechner Kostenloses Training: Chatbot Crashkurs
Kostenloses Training: Chatbot Crashkurs Whitepaper: Die Akzeptanz von Chatbots
Whitepaper: Die Akzeptanz von ChatbotsUm die Latenz bei Voicebots zu optimieren, sollten Unternehmen auf Streaming-Ausgaben, Prompt-Caching und eine modell-agnostische Architektur setzen. Die Kombination aus spezialisierten KI-Modellen und effizienter Multi-Agent-Orchestrierung ermöglicht menschenähnliche Antwortzeiten in Echtzeit.
Latenz optimieren bei Voicebots: Der Schlüssel zu exzellentem Kundenservice
Stellen Sie sich vor, Sie rufen eine Hotline an und stellen eine einfache Frage. Es folgt eine Stille von drei bis fünf Sekunden, bevor der digitale Assistent antwortet. In einem natürlichen Gespräch ist diese Pause eine Ewigkeit. Sie führt dazu, dass Kunden glauben, die Verbindung sei abgebrochen, oder sie fangen an zu sprechen, während der Bot gerade ansetzt.
Bei Voicebots und AI Agents ist die Zeitverzögerung zwischen der Nutzereingabe und der Antwort des Systems, die sogenannte Latenz, das Zünglein an der Waage zwischen technologischer Brillanz und totalem Frust.
Während im Chat eine kurze Wartezeit akzeptiert wird, erfordert die Telefonie Echtzeit-Interaktion. Eine hohe Latenz führt hier unweigerlich zu einer verminderten Benutzerzufriedenheit und Effizienzverlusten im Service. In diesem Artikel erfahren Sie, wie Sie die Latenz optimieren bei Voicebots, um flüssige, menschenähnliche Dialoge zu ermöglichen.
Was bedeutet Latenz bei Voicebots und warum ist sie kritisch?
Latenz bezeichnet bei KI-Systemen die Zeitspanne vom Empfang einer Eingabe bis zum Ausspielen der entsprechenden Ausgabe. Im Kontext von Voicebots ist dieser Prozess besonders komplex, da er nicht nur die semantische Verarbeitung im Hintergrund umfasst, sondern auch die Umwandlung von Sprache in Text und zurück.
Niedrige Latenzzeiten sind entscheidend für die Akzeptanz von KI-Anwendungen. In Echtzeit-Szenarien können bereits Millisekunden den Unterschied zwischen einem natürlichen Gespräch und einer abgehackten, mühsamen Interaktion bedeuten. Für Unternehmen ist eine optimierte Latenz ein direkter Hebel für höhere Erstlösungsquoten (FCR) und eine bessere Prozessautomatisierung. Eine Verzögerung wird oft als mangelnde Kompetenz des Systems wahrgenommen, was die Absprungraten erhöht.
Die Komponenten der Latenz: Wo entstehen Verzögerungen bei Voicebots?
Um die Latenz bei Voicebots zu optimieren, muss man verstehen, aus welchen Teilschritten sich die Gesamtverzögerung zusammensetzt:
- Speech-to-Text (STT): Das gesprochene Wort des Kunden muss in Echtzeit transkribiert werden. Hier spielt der gewählte Provider (z. B. Azure oder Google) eine große Rolle.
- Verarbeitung & Wissensabfrage (NLU/LLM): Das System analysiert die Absicht (Intent) und sucht nach relevanten Informationen. Größere, komplexere Sprachmodelle (LLMs) benötigen für diese Berechnungen typischerweise mehr Zeit als spezialisierte, kleinere Modelle.
- Generierung der Antwort: Hier wird der Antworttext erstellt. Die Anzahl der Output-Tokens beeinflusst direkt die Dauer.
- Text-to-Speech (TTS): Der generierte Text wird wieder in eine natürliche Stimme umgewandelt.
Intelligente Latenzoptimierung bei Voicebots: Mehr als nur Geschwindigkeit
Es gibt verschiedene Strategien, um die Reaktionszeit Ihrer Chatbots & Voicebots spürbar zu senken:
- Streaming-Antworten: Anstatt zu warten, bis das LLM den kompletten Satz generiert hat, wird der Text "gestreamt". Der TTS-Dienst beginnt bereits mit der Sprachausgabe, während die KI das Ende des Satzes noch formuliert.
- Prompt-Caching & effiziente Kontextverwaltung: Durch das Zwischenspeichern häufig genutzter Anweisungen (Prompts) wird die Rechenlast reduziert.
- Modell-Agnostik & Spezialisierung: Die Nutzung von kleineren, optimierten Modellen für einfache Aufgaben und High-End-Modellen (wie GPT-4o oder Claude 3.5 Sonnet) nur für komplexe logische Schlüsse balanciert Geschwindigkeit und Qualität.
- Reduzierung der Output-Tokens: Präzise System-Prompts weisen den AI Agent an, sich kurz und bündig zu fassen, was die Generierungszeit massiv verkürzt.
BOTfriends' Ansatz zur Maximierung der Voicebot-Performance
Um High-End-Technologie ohne den typischen „Enterprise Overhead“ zu liefern, setzt BOTfriends auf eine hochperformante Architektur, die technische Bottlenecks eliminiert und die Nutzererfahrung in den Mittelpunkt stellt. Unser Ansatz zur Optimierung der Latenz bei Voicebots umfasst:
Verwendung von PTU-Modellen

Für unsere Kunden setzen wir auf Provisioned Throughput Units (PTU) anstelle von herkömmlichen PAYGO-Instanzen (Pay-As-You-Go). Der entscheidende Vorteil: Während Sie sich bei Standard-Lösungen die Hardware-Ressourcen des Cloud-Anbieters mit einer Vielzahl anderer Unternehmen teilen müssen, garantieren PTUs eine exklusiv reservierte Rechenkapazität.
Der Unterschied: Öffentliche Spur vs. Exklusiv-Fahrbahn
Um den technologischen Vorteil zu verdeutlichen, lässt sich die KI-Infrastruktur mit einer Autobahn vergleichen:
- Standard-Instanzen (PAYGO): Dies entspricht der öffentlichen Spur. Zu Stoßzeiten (hohes globales Anfrageaufkommen) gerät der Datenverkehr ins Stocken. Die Folge: Ihre KI reagiert verzögert, und Kunden müssen auf Antworten warten.
- PTU-Modelle: Dies ist Ihre private, exklusive Fahrspur. Unabhängig vom allgemeinen Verkehrsaufkommen bleibt Ihre Spur frei und für Sie reserviert. Ihr KI-Agent liefert Ergebnisse somit stets mit der maximal möglichen Geschwindigkeit und ohne Performance-Schwankungen.
Durch die feste Zuweisung der Kapazitäten eliminieren wir die Abhängigkeit von der Auslastung dritter Nutzer. Sie profitieren von einer vorhersehbaren Latenz und einer stabilen, hohen Bandbreite.
Smart Load Balancing
Unser intelligenter Load-Balancing-Ansatz verteilt den Traffic gleichmäßig auf alle verfügbaren Modelle. So vermeiden wir Hotspots und Überlastungen, die zu Verzögerungen führen könnten.
In-Memory Datenbanken
Für die Datenverarbeitung nutzen wir extrem schnelle In-Memory-Datenbanken wie Redis. Dies hält die Zugriffszeiten minimal und beschleunigt die Antwortgenerierung spürbar.
Inkrementelle Ausgabe via WebSockets
Dank WebSockets müssen Requests nicht vollständig abgeschlossen sein, bevor der Nutzer eine Rückmeldung erhält. So kann der Bot bereits eine Nachricht senden, während im Hintergrund noch eine API-Integration läuft. Das Feedback erfolgt sofort, die Interaktion wird deutlich flüssiger.
Minimierung der gefühlten Latenz
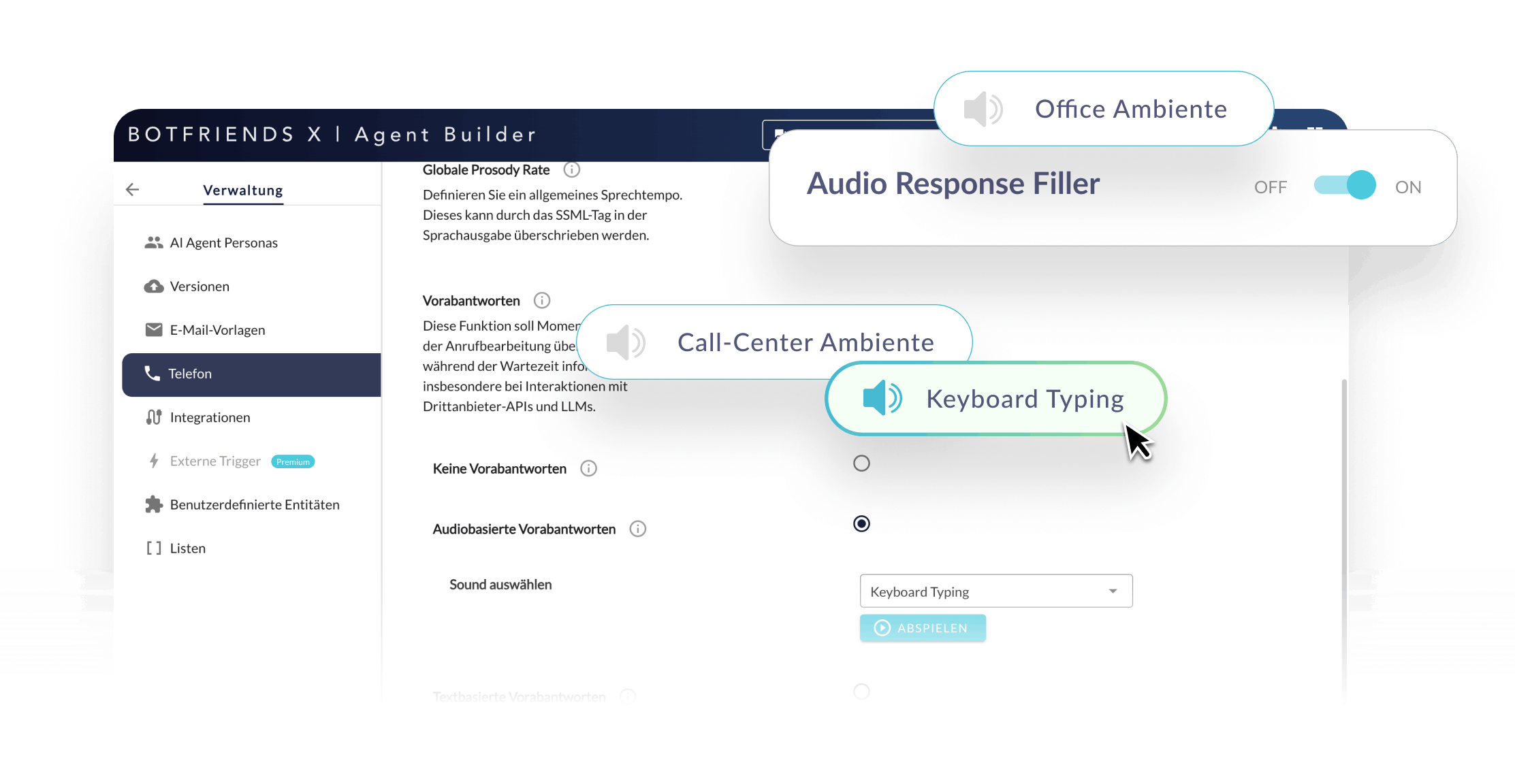
Da die Wahrnehmung der Nutzer entscheidend ist, setzen wir gezielt Pausenfüller ein. Kurze Hinweise wie „Einen Moment, ich schaue nach…“ oder dezente Hintergrundgeräusche wie Tastaturklicken oder Office-Ambiente überbrücken technische Verarbeitungszeiten und sorgen für ein natürliches Gesprächsgefühl.
Erfolgreich Latenz optimieren bei Voicebots: Ihr Weg zu exzellentem Kundenservice
Die Optimierung der Latenz ist kein einmaliges Projekt, sondern ein kontinuierlicher Prozess aus Monitoring und technischer Feinjustierung. Unternehmen, die hier investieren, sichern sich einen Wettbewerbsvorteil durch Technological Sovereignty – sie bleiben unabhängig von einzelnen Providern und bieten ihren Kunden gleichzeitig die bestmögliche Experience.
Mit BOTfriends an Ihrer Seite erhalten Sie nicht nur eine Plattform, sondern einen Partner, der Sie durch Guided Sovereignty zur Unabhängigkeit führt. Wir stellen sicher, dass Ihre AI Agents nicht nur klug antworten, sondern dies auch in einer Geschwindigkeit tun, die einer natürlichen menschlichen Konversation entspricht.
Bereit für Voicebots, die Ihre Kunden nicht warten lassen?
Vereinbaren Sie einen unverbindlichen Beratungstermin und lernen Sie unsere AI Plattform für Voice-, Chat- und E-Mail-Automatisierung kennen.