
 AI Agent ROI Rechner
AI Agent ROI Rechner Kostenloses Training: Chatbot Crashkurs
Kostenloses Training: Chatbot Crashkurs Whitepaper: Die Akzeptanz von Chatbots
Whitepaper: Die Akzeptanz von Chatbots
Artificial General Intelligence (AGI)
--> zum BOTwiki
Definition und Abgrenzung von AGI
Artificial General Intelligence (AGI), auch bekannt als “Künstliche Allgemeine Intelligenz”, bezeichnet ein hypothetisches künstliches System, das die Fähigkeit besitzt, jede intellektuelle Aufgabe zu verstehen und zu erlernen, die auch ein Mensch verstehen und erlernen kann. Es wird davon ausgegangen, dass eine AGI in allen kognitiven und intellektuellen Bereichen mindestens gleichwertige oder überlegene Fähigkeiten im Vergleich zum Menschen aufweist. Die Entwicklung einer AGI stellt ein zentrales Forschungsziel im Bereich der Künstlichen Intelligenz dar, ist jedoch zum aktuellen Zeitpunkt noch nicht realisiert worden.
Im Gegensatz dazu wird die heute weit verbreitete Künstliche Intelligenz als Artificial Narrow Intelligence (ANI) oder schwache KI bezeichnet. ANI-Systeme sind auf spezifische Aufgaben und Anwendungsbereiche beschränkt und können in anderen Domänen keine Leistung erbringen. Beispiele hierfür sind aktuelle Chatbots, Sprachassistenten oder Bilderkennungssysteme. Eine AGI hingegen wäre universell einsetzbar und könnte Wissen und Fähigkeiten über verschiedene Bereiche hinweg transferieren und anwenden.
Eigenschaften und Merkmale einer AGI
Eine Artificial General Intelligence würde das gesamte Spektrum menschlicher kognitiver und intellektueller Fähigkeiten nachbilden. Dazu gehören Lernfähigkeit, das Verstehen natürlicher Sprache, die Fähigkeit zum Argumentieren und Planen, Problemlösungskompetenz sowie die Anpassung an neue Situationen. Ein solches System würde über einen „natürlichen Menschenverstand“ verfügen und in der Lage sein, komplexe Probleme in Umgebungen und Kontexten zu lösen, für die es nicht explizit trainiert wurde. Offene Fragen bestehen hinsichtlich des Bewusstseins oder Empfindungsvermögens einer AGI, was auch philosophische Dimensionen der Forschung berührt.
Derzeitiger Stand und Forschungsperspektiven
Trotz erheblicher Fortschritte im Bereich der Künstlichen Intelligenz wird Artificial General Intelligence weiterhin als Zukunftsmusik betrachtet. Aktuelle KI-Systeme, einschließlich fortschrittlicher Sprachmodelle, zeigen zwar erstaunliche Leistungen in spezifischen Teilbereichen, erreichen jedoch nicht das Niveau einer AGI. Es wird angenommen, dass die Entwicklung einer AGI verschiedene KI-Konzepte und -Technologien wie Maschinelles Lernen, Deep Learning, Künstliche Neuronale Netzwerke, natürliche Sprachverarbeitung (NLP) und Computer Vision integrieren müsste. Die genaue Zeitspanne bis zur möglichen Realisierung einer AGI wird von Forschenden unterschiedlich eingeschätzt, wobei Prognosen von wenigen Jahren (Interview von Demis Hassabis, CEO Deepmind, und Sergey Brin, Co-Founder Google) bis zu mehreren Jahrzehnten reichen.
AGI im Kontext von Conversational AI und AI Agents
Im Bereich der Conversational AI und bei der Entwicklung von AI Agents bei BOTfriends wird mit spezialisierten KI-Systemen gearbeitet. Diese Systeme, wie Chatbots und Voicebots, sind Beispiele für Artificial Narrow Intelligence, da sie für bestimmte Konversationsabläufe und Aufgaben trainiert werden. Eine zukünftige Artificial General Intelligence könnte die Möglichkeiten von Conversational AI und AI Agents grundlegend verändern. AGIs könnten in der Lage sein, hochkomplexe Dialoge autonom zu führen, Wissen flexibel anzuwenden und sich selbstständig an neue Gesprächsanforderungen und Themen anzupassen, ohne dass eine umfangreiche Neukonfiguration oder Umschulung erforderlich ist. Die Vision einer AGI bildet daher einen langfristigen Horizont für die Weiterentwicklung intelligenter Automatisierungslösungen.
Häufig gestellte Fragen (FAQ)
Artificial General Intelligence (AGI) zeichnet sich durch die Fähigkeit aus, jede intellektuelle Aufgabe auf menschlichem Niveau oder besser zu lösen, ohne auf einen spezifischen Bereich beschränkt zu sein. Im Gegensatz dazu ist herkömmliche oder „schwache“ KI (Artificial Narrow Intelligence) auf die Ausführung bestimmter Aufgaben in vordefinierten Domänen spezialisiert. Aktuelle Chatbots oder Bilderkennungssysteme fallen in die Kategorie der schwachen KI, während AGI ein universell anwendbares und lernfähiges System wäre.
Es existiert kein allgemeiner Konsens über den genauen Zeitpunkt, wann eine voll funktionsfähige Artificial General Intelligence (AGI) Realität werden könnte. Expertenschätzungen variieren erheblich, von einer möglichen Entwicklung innerhalb der nächsten fünf bis zehn Jahre bis zu Prognosen, die noch 20 Jahre oder länger veranschlagen. Derzeitige KI-Systeme gelten trotz fortgeschrittener Fähigkeiten noch nicht als AGI.
Für Conversational AI Systeme, wie sie beispielsweise von BOTfriends entwickelt werden, würde Artificial General Intelligence (AGI) eine transformative Bedeutung haben. Heutige Conversational AI ist auf spezifische Anwendungsfälle trainiert. Eine AGI könnte hingegen selbstständig neue Gesprächsstrategien entwickeln, Wissen kontextübergreifend nutzen und sich flexibel an unvorhergesehene Gesprächssituationen anpassen, was eine weit höhere Autonomie und Problemlösungsfähigkeit in der Interaktion bedeuten würde. Die AGI stellt somit ein Langzeitziel in der Entwicklung hochintelligenter Konversationssysteme dar.
> Zurück zum BOTwiki
Hybrid Human Chatbot
--> zum BOTwiki
Ein Hybrid Human Chatbot ist eine Lösung, bei der Chatbot und menschliche Servicemitarbeiter gemeinsam die Kundenkommunikation übernehmen. Der Chatbot bearbeitet zunächst eingehende Anfragen automatisiert. Wenn er eine Frage nicht beantworten kann oder die Situation eine persönliche Betreuung erfordert, erfolgt eine nahtlose Übergabe an einen menschlichen Agenten: der sogenannte Human Handover. Für den Nutzer findet dieser Wechsel innerhalb desselben Chat-Fensters statt, ohne Medienbruch. Die menschlichen Mitarbeiter erhalten dabei den vollständigen Gesprächsverlauf und Kontext, sodass keine Informationen verloren gehen. Gleichzeitig lernt der Chatbot aus den menschlichen Antworten und erweitert kontinuierlich seine Wissensbasis.
Warum ist Hybrid Human Chatbot wichtig?
Für Unternehmen in Deutschland ist der hybride Ansatz besonders wertvoll, da er Effizienz mit Servicequalität verbindet. Etwa 80% der Kundenanfragen sind wiederkehrend und können von einem Chatbot in Sekundenschnelle beantwortet werden - 24/7, ohne Wartezeiten. Gleichzeitig bleiben menschliche Mitarbeiter für komplexe Anliegen, emotionale Situationen oder hochwertige Beratungsgespräche verfügbar. Dies führt zu gesteigerter Kundenzufriedenheit, da jede Anfrage den passenden Bearbeiter erhält. Für Serviceteams bedeutet es Entlastung von Routineanfragen und mehr Zeit für anspruchsvolle Fälle. Besonders in Peak-Zeiten wie dem Weihnachtsgeschäft zeigt sich der Vorteil: Der Chatbot fungiert als intelligente Firewall, die Anfragen filtert und priorisiert.
Hybrid Human Chatbot in der Praxis
Ein typisches Anwendungsbeispiel ist der Customer Service im E-Commerce: Der Chatbot beantwortet Fragen zu Versandzeiten, Rücksendungen oder Produktverfügbarkeit automatisch. Bei Kunden mit hohen Warenkorbwerten oder komplexen Produktberatungen erfolgt die Übergabe an einen Servicemitarbeiter.
BOTfriends ermöglicht solche hybriden Lösungen durch nahtlose Integration mit verschiedensten Live-Chat-Systemen, wie Zendesk oder Userlike. Die Plattform analysiert kontinuierlich nicht-beantwortete Fragen und schlägt automatisch neue Themen vor, sodass der Chatbot stetig dazulernt und sich verbessert.
Häufig gestellte Fragen (FAQ)
Der Human Handover erfolgt nahtlos im selben Chat-Fenster. Der Chatbot erkennt anhand von Intent-Analyse, Sentiment oder definierten Triggern, wann eine menschliche Übernahme erforderlich ist. Der Agent erhält den vollständigen Gesprächsverlauf, Kundenhistorie und kontextbezogene Informationen. BOTfriends bietet diese Funktion mit Integration zu gängigen Live-Chat-Systemen, sodass keine doppelte Infrastruktur nötig ist.
Hybride Lösungen kombinieren das Beste aus beiden Welten: 24/7-Verfügbarkeit und Skalierbarkeit der KI mit menschlicher Empathie und Problemlösungskompetenz. Dies verhindert Frustration durch Bot-Limitierungen, erhöht die Lösungsrate beim Erstkontakt und ermöglicht kontinuierliches Lernen. Unternehmen können mit kleinerem Bot-Scope starten und diesen organisch erweitern, basierend auf echten Nutzeranfragen.
Der hybride Ansatz eignet sich besonders für Customer Service, E-Commerce, Human Resources, IT-Support und Sales. Überall dort, wo ein breites Fragenspektrum erwartet wird oder bestimmte Prozessschritte menschliche Entscheidungen erfordern, ist diese Lösung ideal. BOTfriends unterstützt Unternehmen bei der Identifikation geeigneter Use Cases und bietet mit der Wizard-of-Oz-Methode eine Testmöglichkeit vor der vollständigen Automatisierung.
--> Zurück zum BOTwiki
Prebuilts
--> zum BOTwiki
Prebuilts, oder auch vorgefertigte Wissensbasen, sind eine Sammlung aus Inhalten für bestimmte Chatbot Anwendungsfälle. Chatbots leben von Inhalten, die ihnen beigebracht werden. Um einen Chatbot zu entwickeln, ist es wichtig, diesen mit Inhalten, sprich Fragen und Antworten anzureichern. Umso mehr Inhalt, desto breiter ist sein Wissen und somit auch die Antworten, die er geben kann. Prebuilts helfen bei der Entwicklung und können als “Booster” hinzugezogen werden. Wenn man z.B. einen Chatbot im Bereich IT-Support aufbauen möchte, ist es sehr hilfreich auf solche vorgefertigte Wissensbasen zurückgreifen zu können, sodass abhängig vom Use Case schon ein Grundstock an Inhalten zur Verfügung steht.
Wie sind Prebuilts aufgebaut?
Prebuilts bestehen aus Fragemöglichkeiten, Entitäten und Antworten. Um die Spracherkennung eines Chatbots zu erhöhen, ist es wichtig viele verschiedene Fragemöglichkeiten für eine Absicht zu hinterlegen. Des Weiteren gehören zu jeder Absicht (Intent) Entitäten und Antworten. Bei Prebuilts existieren vorgefertigte beispielhafte Antworten, die der Kunde oder die Kundin 1:1 übernehmen kann, aber natürlich auch an das Unternehmen, den Charakter und Tonalität des Chatbots anpassen muss.
Wie können Prebuilts eingesetzt werden?
Prebuilts sind in der Regel einfach einzubinden. In den meisten Fällen werden die Prebuilts über den genutzten NLP-Service integriert. Hierbei gibt es häufig eine One-Click Integration, mit welcher man schnell und einfach benötigte Inhalte importieren kann. Eine weitere Möglichkeit mit Prebuilts zu arbeiten ist die Integration innerhalb von Intent Management Plattformen (IMP). Diese Plattformen sind dazu da, einfach und schnell contentspezifische Änderungen vorzunehmen.
Welche Prebuilts werden schon sinnvoll eingesetzt?
Es gibt bereits eine Vielzahl an verfügbaren Sample Prebuilts, die man in einen Chatbot integrieren kann. Das Smalltalk Prebuilt ist mit Sicherheit eines der Prebuilts, das schon am Häufigsten eingesetzt wird. Dies ist auch sehr sinnvoll, denn wenn man sich eine typische Kommunikation eines Nutzers mit einem Chatbot anschaut, werden gerade zu Beginn einige Smalltalk Fragen wie "Wie geht es dir?", "Wie alt bist du?" gestellt. Allerdings gibt es auch weitere Prebuilts, wie beispielsweise Wetter, News oder Restaurantbuchungen. Hierbei muss man darauf achten, in welchen Sprachen diese Prebuilts jeweils verfügbar sind. Insgesamt betrachtet können Prebuilts in einigen Bereichen Starthilfe geben und bei der Entwicklung eines Chatbots unterstützen.
> Zurück zum BOTwiki
Chatbot
--> zum BOTwiki
Ein Chatbot ist ein Computerprogramm, das dafür entwickelt wurde, Konversationen mit Menschen über digitale Kanäle zu führen und Anfragen automatisiert zu beantworten. Der Begriff setzt sich aus dem englischen Wort „Chat" für Gespräch und „Bot" als Kurzform von „Robot" zusammen. Chatbots werden auf Webseiten, in Messenger-Diensten oder in andere digitale Oberflächen integriert und verarbeiten Nutzereingaben häufig mithilfe von künstlicher Intelligenz.
Abgrenzung zu herkömmlichen Bots
In der Informatik bezeichnet der Begriff „Bot" allgemein ein selbstständig laufendes Programm, das seine Aufgaben ohne menschliches Eingreifen ausführt und lediglich einmalig initiiert werden muss. Bots können dabei unterschiedliche Zwecke verfolgen, darunter auch schädliche, etwa im Rahmen von Botnetzen, die koordinierte Denial-of-Service-Angriffe ermöglichen.
Ein Chatbot ist eine spezialisierte Form dieses Konzepts. Er ist explizit auf die Kommunikation mit Menschen ausgelegt und darauf ausgerichtet, Konversationen in natürlicher Sprache zu verarbeiten und sinnvoll zu beantworten. Der wesentliche Unterschied liegt in der Interaktionsfähigkeit: Während allgemeine Bots Aufgaben im Hintergrund ausführen, ist der Chatbot auf den direkten Austausch mit Nutzerinnen und Nutzern ausgelegt.
Rolle der künstlichen Intelligenz
Die Verarbeitung natürlichsprachlicher Eingaben ist nur durch den Einsatz von künstlicher Intelligenz möglich. Menschliche Sprache folgt keinen starren Regeln und kann nicht direkt durch klassische Programmlogik verarbeitet werden. Stattdessen kommt Natural Language Processing zum Einsatz, kurz NLP. Dabei wird die Eingabe eines Nutzers von sogenannten Large Language Modellen interpretiert, um die dahinterliegende Absicht, den sogenannten Intent, zu erkennen.
Sobald ein Intent erkannt wurde, wird dieser in eine Aktion überführt. Diese Aktion kann eine direkte Antwort auf eine Frage sein oder die Ausführung eines Prozesses, etwa das Abrufen von Informationen aus einem angebundenen System. Damit ein Chatbot sinnvoll antworten kann, muss hinter der NLP-Komponente eine strukturierte Wissensbasis mit Antworten und definierten Aktionen hinterlegt sein.
Einsatzbereiche und Kanalintegration
Chatbots kommen auf allerlei textbasierten Kanälen zum Einsatz. Im Kundenservice werden sie häufig als Webchat auf der Unternehmenswebseite platziert oder auf den Social Media Kanälen wie Facebook Messenger oder Instagram integriert. Auch im HR Bereich können sie per Slack oder Microsoft Teams eingebunden werden.
Für die Entwicklung und den Betrieb von Chatbots stehen verschiedene Plattformen zur Verfügung. Anbieter wie Google mit Dialogflow, IBM mit Watson oder Microsoft mit LUIS stellen ihre Systeme als öffentlich zugängliche Webservices bereit. Diese Plattformen ermöglichen den Zugang zu ausgereiften Machine-Learning-Systemen, ohne dass eine eigene Infrastruktur aufgebaut werden muss.
BOTfriends bietet eine hochperformante Enterprise-Plattform, auf der Sie intelligente Chatbots im Eigenbetrieb erstellen und über alle Kanäle hinweg zentral steuern können. Dank der intuitiven No-Code-Architektur automatisieren Sie komplexe Kundenanliegen bis ins Backend, ohne auf teure externe Integratoren angewiesen zu sein.
Ein Chatbot verarbeitet Eingaben in Textform und gibt Antworten ebenfalls als Text aus. Ein Voicebot hingegen ist auf gesprochene Sprache ausgelegt und nutzt zusätzlich Technologien zur Spracherkennung sowie zur Sprachsynthese. In der Praxis können beide Formen auf derselben Konversationslogik basieren und sich lediglich in der Ein- und Ausgabemodalität unterscheiden. BOTfriends X unterstützt beide Varianten innerhalb einer gemeinsamen Plattform.
Nicht zwingend. Es gibt regelbasierte Chatbots, die auf festen Entscheidungsbäumen und vordefinierten Antwortpfaden basieren, ohne KI-Komponenten zu nutzen. Diese eignen sich für einfache, klar strukturierte Anwendungsfälle. Sobald jedoch natürlichsprachliche Eingaben in variabler Form verarbeitet werden sollen, ist der Einsatz von NLP und damit von KI-Methoden erforderlich, um eine verlässliche Erkennung von Nutzerabsichten zu gewährleisten.
Chatbots kommen in verschiedenen Bereichen zum Einsatz, etwa im Kundenservice zur Beantwortung häufiger Anfragen, im internen IT-Support, in der Personalgewinnung oder im E-Commerce. Sie werden dort eingesetzt, wo ein hohes Volumen an gleichartigen Anfragen anfällt und eine automatisierte Bearbeitung sinnvoll ist. Die Integration erfolgt über Kanäle wie Webchat, WhatsApp, Microsoft Teams oder andere Messaging-Plattformen.
> Zurück zum BOTwiki
Conversational Office
--> zum BOTwiki
Ein Conversational Office, auch Conversational Workplace genannt, beschreibt, dass in Unternehmen ein Großteil der internen Kommunikation und Serviceprozesse über dialogfähige Systeme abgewickelt wird. Statt sich durch Intranet-Menüs, Self-Service-Portale oder Ticket-Formulare zu klicken, sprechen oder schreiben Mitarbeitende direkt mit einem AI Agent, der Anliegen versteht, Daten aus den richtigen Backend-Systemen zieht und Vorgänge anstoßt.
Für Unternehmen entsteht so ein neuer Kommunikationsstandard, der HR, IT-Support und Facility Management auf einer einheitlichen Conversational-Schicht bündelt.
Was ein Conversational Office ausmacht
Ein Conversational Office ist mehr als ein einzelner FAQ-Bot im Intranet. Es kombiniert mehrere AI Agents, die jeweils einen fachlichen Bereich abbilden. Etwa Personalwesen, IT-Service, Reisemanagement oder Office-Logistik. Über Multi-Agent-Orchestrierung greifen diese Agents auf gemeinsame Identitäten, Berechtigungen und Wissensquellen zu und reichen Anliegen sauber an den jeweils zuständigen Spezialagenten weiter.
Technisch basiert ein Conversational Office auf einer durchgängigen Conversational-AI-Plattform, die Voice, Chat und E-Mail unter einer gemeinsamen Logik vereint. Knowledge AI sorgt dafür, dass interne Richtlinien, Handbücher und Tool-Dokumentationen abrufbar sind, ohne dass ein Mitarbeitender wissen muss, in welchem System die Antwort steht.
Typische Anwendungsfelder im Unternehmen
Die Einsatzbereiche reichen von Recruiting bis Office Management. Ein Conversational Office bündelt diese Use Cases in einer einheitlichen Dialogerfahrung statt in zehn verschiedenen Tools.
- HR und Recruiting: Stellensuche, Bewerbungsstatus, Urlaubsanträge, Gehaltsbescheinigungen und Onboarding-Schritte werden im Dialog abgefragt.
- IT-Support: Passwort-Reset, Gerätebestellung, Software-Freigaben oder Stoerungsmeldungen laufen über AI Workflows und werden bei Bedarf eskaliert.
- Office-Services: Raumbuchung, Kantinenmenue, Shuttle-Zeiten, Besucheranmeldung oder Taxi-Bestellung werden im Self-Service erledigt.
- Wissenszugriff: Mitarbeitende fragen nach Richtlinien, Prozessen oder Vertragsbedingungen und erhalten quellenbasierte Antworten.
Bedeutung für Voice und Chat
Im Conversational Office spielt der Voice-Kanal eine wachsende Rolle. Eine interne Service-Hotline, die früher von einem klassischen IVR-System bedient wurde, lässt sich heute durch einen Phonebot ablösen, der Anliegen sofort versteht und ohne Tastendruck-Menue zur richtigen Stelle leitet. Die klassische IVR ist Body ohne Brain. AI-Native Voice mit Multi-Agent-Orchestrierung dagegen kombiniert natürliches Sprachverständnis mit echter Vorgangsbearbeitung. Ein Mitarbeitender, der unterwegs sein Passwort zurücksetzen muss, erledigt das im Telefonat statt im Browser.
Im Chat, etwa über Microsoft Teams, Slack oder ein internes Web-Widget. Ergänzt sich die Voice-Erfahrung um Intent-basierte Dialoge mit Anhängen, Buttons und strukturierten Antworten. E-Mail-Anfragen an Service-Postfächer können zusätzlich automatisch klassifiziert und durch denselben AI Agent beantwortet werden, sodass über alle Kanäle hinweg eine konsistente Wissensbasis greift.
Conversational Office in Multi-Agent-Setups
Ein produktives Conversational Office besteht selten aus einem einzigen Allrounder-Agent. Hybride Intelligenz aus regelbasierter Prozesslogik und generativen Modellen bildet das Brain, während einzelne Fachagenten als Body für HR, IT oder Facility agieren. Eine Orchestrierungsschicht entscheidet, welcher Agent ein Anliegen bearbeitet, wann ein menschlicher Mitarbeitender übernimmt und welche Informationen zwischen den Systemen fließen. So skaliert das Conversational Office mit den Strukturen des Unternehmens, statt jede Abteilung in einem isolierten Tool zu verwalten.
> Zurück zum BOTwiki
Conversational Testing
--> zum BOTwiki
Conversational Testing bezeichnet das systematische Prüfen der im Conversation Flow festgelegten Abläufe eines AI Agents auf Natürlichkeit und Verständlichkeit, bevor diese in den produktiven Betrieb gehen.
Ziel ist es, frühzeitig zu erkennen, ob Formulierungen natürlich klingen, der Dialog zum Ziel führt und der gewünschte Tonalitätsrahmen eingehalten wird. Das Verfahren ist ein zentraler Baustein des Conversational Designs und ergänzt automatisierte Testmethoden um die menschliche Beurteilungsebene. Damit verbindet Conversational Testing klassische Qualitätssicherung mit den Anforderungen moderner Conversational AI an Hybride Intelligenz.
Was Conversational Testing aufdeckt
Im Conversational Testing wird sichtbar, an welchen Stellen in der kommunikativen Ausarbeitung des AI Agents noch Verbesserungsbedarf herrscht. Darunter fallen:
- Verschachtelte oder belästigend lange Sätze, die im Voice-Kanal nicht funktionieren.
- Fehlende oder unklare Rückfragen, wenn der Intent nicht eindeutig ist.
- Tonalitätsbrüche zwischen formellen und informellen Passagen.
- Lücken im Conversation Flow, in denen Nutzende keinen sinnvollen nächsten Schritt erkennen.
- Antworten, die fachlich korrekt sind, aber am eigentlichen Anliegen vorbeigehen.
Bedeutung für Voice und Chat
Im Voice-Kanal, etwa bei einem Voicebot in der Hotline-Triage, ist Conversational Testing besonders wertvoll. Gesprochene Sprache verzeiht keine umständlichen Konstruktionen, und Nutzende erwarten kurze, eindeutige Reaktionen.
Im Chat- und E-Mail-Kontext verschiebt sich der Fokus auf Lesbarkeit, Tonalität und die richtige Balance zwischen Präzision und Empathie. Auch hier zeigt das Testing, ob Antworten als hilfreich empfunden werden oder ob Nutzende zusätzliche Rückfragen benötigen, um das Anliegen zu klären.
Conversational Testing in Multi-Agent-Setups
In komplexen Szenarien arbeiten mehrere spezialisierte AI Agents zusammen, etwa für Authentifizierung, Sachbearbeitung und Eskalation. Conversational Testing wird hier auf der Ebene der Übergaben besonders relevant, weil Brüche zwischen Agents schnell zu Wiederholungen oder verlorenen Kontextinformationen führen können. Im Zusammenspiel mit Knowledge AI und definierten AI Workflows hilft das Verfahren, Prozessgrenzen zu erkennen und die Verantwortungsbereiche der einzelnen Agents sauber abzugrenzen.
Für die produktive Umsetzung empfiehlt sich ein iterativer Rhythmus: Die Ergebnisse des Testings fließen in überarbeitete Trainingsphrasen, angepasste Fallback-Pfade und nachjustierte Workflow-Schritte ein. So entsteht eine kontinuierliche Verbesserung, die Conversational AI über die Zeit deutlich robuster macht.
Häufig gestellte Fragen (FAQ)
Sinnvoll ist der Einsatz, sobald ein Conversation Flow grob steht und die wichtigsten Antworten formuliert sind. In der Praxis erfolgt das Testing zwischen Conversational Copywriting und der technischen Implementierung, um Schwachstellen früh zu erkennen. Es lässt sich aber auch später für neue Use Cases oder bei größeren Dialogüberarbeitungen erneut durchführen.
Automatisierte Tests prüfen vor allem die Erkennungsleistung des NLU-Modells und die technische Stabilität von Workflows. Conversational Testing ergänzt diese Ebene um die menschliche Bewertung von Tonalität, Sprachfluss und gefühlter Hilfeleistung. Beide Verfahren sind komplementär und sollten in einer professionellen Conversational-AI-Entwicklung gemeinsam eingesetzt werden.
> Zurück zum BOTwiki
Insult Rate
--> zum BOTwiki
Die Insult Rate ist eine Metrik aus der Chatbot- oder Voicebot-Analytics, die angibt, in wie vielen Konversationen Nutzer den Bot beleidigen oder beschimpfen. Sie wird als Verhältnis von Gesprächen mit Beleidigungen zur Gesamtzahl der Interaktionen berechnet. Beleidigungen treten häufig auf, wenn der AI Agent keine passende Antwort liefert, Missverständnisse produziert oder technisch an seine Grenzen stößt. Manchmal erfolgen Beschimpfungen auch grundlos, etwa durch sogenannte Trolle, die die Anonymität des Internets ausnutzen. Die Insult Rate ist damit ein Indikator für Frustration, unerfüllte Erwartungen oder mangelnde User Experience.
Warum ist die Insult Rate wichtig?
Die Insult Rate ist eine zentrale Kennzahl zur Bewertung der Effizienz und User Acceptance. Eine hohe Rate signalisiert oft technische oder inhaltliche Defizite: fehlerhafte Antworten, schlechte Anliegenerkennung oder unzureichende Dialogführung. Sie kann aber auch von der Zielgruppe oder dem Anwendungsfall abhängen. In sensiblen Bereichen oder bei jüngeren Nutzern steigt die Hemmschwelle zur Beschimpfung oft. Für Unternehmen ist die Insult Rate wertvoll, weil sie konkrete Optimierungsansätze aufzeigt: Welche Dialoge erzeugen Frust? Wo fehlen Antworten? Die systematische Auswertung dieser KPI hilft, die Performance des Chatbots oder Voicebots kontinuierlich zu verbessern und die Kundenzufriedenheit zu steigern.
Insult Rate in der Praxis
In der Praxis wird die Insult Rate genutzt, um gezielt Schwachstellen in Chatbot-Dialogen zu identifizieren. Beispiel: Ein Kundenservice-Bot weist in 15 % aller Gespräche Beleidigungen auf. Die Analyse zeigt, dass Nutzer besonders bei Fragen zu Lieferzeiten frustriert reagieren. Der Chatbot liefert hier keine klaren Antworten. Nach einer Optimierung der Intents und Antworten sinkt die Rate auf 5 %.
BOTfriends setzt auf datengetriebene Chatbot-Optimierung: Durch Auswertung der Insult Rate und gezieltes Training der KI-Modelle werden Dialoge kontinuierlich verbessert. So entsteht eine positive User Experience, die Beleidigungen minimiert und die Akzeptanz des Chatbots nachhaltig erhöht.
Häufig gestellte Fragen (FAQ)
Die Insult Rate wird als Prozentsatz ermittelt: Anzahl der Konversationen mit Beleidigungen geteilt durch die Gesamtzahl aller Gespräche, multipliziert mit 100. Beispiel: 3 Beleidigungen bei 30 Chats ergeben eine Insult Rate von 10 %. Die Erkennung erfolgt meist durch Keyword-Analyse oder Natural Language Processing (NLP).
Eine hohe Insult Rate deutet auf Probleme hin: schlechte Antwortqualität, fehlende Intents, technische Fehler oder eine frustrierende User Experience. Sie ist ein Warnsignal, dass der Chatbot oder Voicebot überarbeitet werden muss. BOTfriends analysiert solche Fälle systematisch, um gezielte Verbesserungen umzusetzen.
Ja, die Insult Rate hängt stark von Zielgruppe und Anwendungsfall ab. In sensiblen Bereichen wie Gesundheit oder Finanzen ist sie oft niedriger, bei jüngeren Zielgruppen oder in informellen Kontexten höher. Auch die Tageszeit und Anonymität beeinflussen das Nutzerverhalten erheblich.
> Zurück zum BOTwiki
Quick Reply / Schnellantworten / Chips
--> zum BOTwiki
Quick Replies sind eine Interaktionsform in Messaging Plattformen und erscheinen als Buttons unter einer Nachricht. Im Gegensatz zu Cards verschwinden die Quick Replies, nachdem sie betätigt wurden. Mit Hilfe der Quick Replies haben User die Möglichkeit sich durch Inhalte im Chatbot durchzuklicken anstatt ihre Anfrage im Eingabefeld einzutippen. Wird zum Beispiel vom Chatbot ein Button mit der Bezeichnung "Hilfe" angeboten ist es am Ende nichts anderes wie wenn der User "Hilfe" eintippt und abschickt. Die Kommunikation wird damit beschleunigt und die Nutzer bekommen eine Orientierung über die Themenfelder, die der Chatbot anbietet.
Je nach Output Kanal bzw. Messaging Plattform werden unterschiedliche Namensgebungen für Quick Replies verwendet.
| Messaging Plattform | Bezeichnung |
| Facebook Messenger | Schnellantworten, Quick Reply |
| Google Assistant | Suggestion Chips |
| Microsoft Botframework | Suggested Actions |
| Slack | Slack interactive buttons |
| Skype | HeroCard |
| Telegram | Keyboard Buttons |
| Viber | Keyboards |
Hier ein Beispiel Bild für Quick Replies im Facebook Messenger:

Anwendung in Dialogflow
Wenn man in Dialogflow Intents erstellt oder bearbeitet findet man unter der Rubrik Response mehrere Möglichkeiten als Chatbot zu antworten. Unter anderem hat man die Möglichkeit das Format Quick Reply auszuwählen und in Form einer Liste die Buttons zu benennen.
Eine Quick Reply Response wird in den Messaging Plattformen als vordefinierte User Antwort dargestellt, die durch das Anklicken an Dialogflow zurückgesendet wird.
> Zurück zum BOTwiki
AI Agent Training
--> zum BOTwiki
AI Agent Training bezeichnet die kontinuierliche Verbesserung der Antwortqualität, des Kontextverständnisses und des Verhaltens eines intelligenten digitalen Assistenten. Im Zeitalter generativer KI geht es dabei weniger um das manuelle Zuweisen von Intents, sondern primär um die Optimierung von Instruction-Prompts, die Verfeinerung der Knowledge Base und die Justierung der AI Persona.
Ziel ist es, dass ein AI Agent Nutzeranfragen nicht nur versteht, sondern im richtigen Tonfall, mit korrekten Fakten und innerhalb der definierten Leitplanken beantwortet. Das Training ist ein laufender Prozess, der sicherstellt, dass die generative Freiheit der KI stets mit den geschäftlichen Anforderungen und der Realität der Nutzerinteraktionen im Einklang bleibt.
Was beim AI Agent Training passiert
Im Kern geht es darum, die Interaktionslogik und die Wissensgrundlage des Agenten zu schärfen. Statt starrer Erkennungsmuster wird das „Gehirn“ des Agenten durch iteratives Prompt Engineering und Datenpflege trainiert.
Ein typischer Trainingszyklus umfasst heute:
-
Log-Analyse & Evaluation: Auswertung von Dialogen auf Halluzinationen, Tonfall-Abweichungen oder Wissenslücken.
-
Prompt-Iterationen: Anpassung der Instruktionen im Instructions-Prompt und der AI Agent Persona, um das Verhalten des Agenten sowie den Kommunikationsstil zu steuern.
-
Knowledge-Refinement: Optimierung der Wissensquellen (Dokumente, FAQs), damit die Retrieval Augmented Generation (RAG) präzisere Informationen liefert.
-
Guardrail-Tuning: Verfeinerung von Sicherheitsfiltern, um sicherzustellen, dass der Agent keine unerwünschten oder falschen Versprechen abgibt.
Wann und wie häufig trainiert wird
Das Training beginnt in der Konzeptionsphase mit dem Entwurf der AI Persona und der Dialoglogik. Doch erst nach dem Go-Live zeigt sich, wie Nutzer tatsächlich mit der generativen KI interagieren. Da LLMs (Large Language Models) auf unvorhersehbare Weise auf Eingaben reagieren können, ist ein engmaschiges Monitoring essenziell.
-
Initiales Training: Aufbau der Persona, Definition der Aufgabenbereiche und Anbindung der ersten Wissensquellen.
-
Pilotphase: Testläufe mit "Human-in-the-Loop", um die Qualität der generierten Antworten unter realen Bedingungen zu validieren.
-
Kontinuierliche Optimierung: Regelmäßige (wöchentliche) Analyse der Nutzerfeedbacks und Anpassung der Wissensbasis.
-
Ad-hoc-Training: Sofortige Korrektur von Instruktionen bei neuen Firmenrichtlinien oder Produktänderungen.
Bedeutung für Voice und Chat
Im Voice-Kanal (z. B. KI-Hotline) ist das Training besonders kritisch. Hier müssen AI Agents lernen, mit Redefluss, Unterbrechungen und akustischen Missverständnissen umzugehen. Das Training fokussiert sich darauf, den Agenten so zu instruieren, dass er auch bei ungenauem Speech-to-Text-Input (Dialekte, Rauschen) den Kern des Anliegens erfasst und durch Agentic Dialogues (aktive Rückfragen) zum Ziel führt.
Im Chat- und E-Mail-Kontext liegt der Schwerpunkt auf der Informationsdichte und der formalen Korrektheit. Das Training stellt sicher, dass der Agent komplexe Dokumente richtig zusammenfasst und in schriftlicher Form präzise Handlungsanweisungen gibt, ohne den Nutzer mit zu langen Textwänden zu überfordern.
AI Agent Training in Multi-Agent-Setups
In modernen Architekturen mit Multi-Agent-Orchestrierung wird das Training modular. Man trainiert nicht mehr ein monolithisches System, sondern spezialisierte Agents für Teilaufgaben (z. B. einen „Technik-Experten“ und einen „Vertrags-Assistenten“). Jeder Agent erhält ein spezifisches Training für seine Domäne:
-
Der eine wird auf präzise API-Aufrufe (Tools) trainiert.
-
Der andere wird auf empathische Beschwerdeführung (Persona) optimiert. Ein übergeordneter Orchestrator steuert den Kontext. Hybride Intelligenz bedeutet hier, dass das Training sowohl das Faktenwissen (Knowledge AI) als auch die prozessuale Intelligenz (Agentic Workflows) kontinuierlich verbessert.
Häufig gestellte Fragen (FAQ)
Es ist die kontinuierliche Feinabstimmung von Instruktionen (Prompts) und Wissensquellen (RAG), um die Qualität und Sicherheit der Antworten eines KI-Agenten zu maximieren.
KI-Modelle sind universell begabt, kennen aber Ihre spezifischen Unternehmensregeln, Produkte und Ihre Tonalität nicht. Das Training „erzieht“ die KI dazu, sich exakt so zu verhalten, wie es Ihre Marke erfordert.
Teilweise. Während Knowledge AI (RAG) den Agenten automatisch mit aktuellem Wissen füttert, bleibt das manuelle Training der Instruktionen wichtig, um zu steuern, wie dieses Wissen vermittelt wird (z. B. freundlich, sachlich oder verkaufsorientiert).
Bei Voice liegt der Trainingsschwerpunkt auf der Robustheit gegenüber Sprachfehlern und der Dialogsteuerung in Echtzeit. Der Agent muss trainiert werden, Pausen richtig zu deuten und Anrufer aktiv durch Prozesse zu führen, statt nur passiv auf Texteingaben zu warten.
> Zurück zum BOTwiki
Edge Case
--> zum BOTwiki
Unter Edge Cases versteht man nicht erwartungsgemäße Ausgänge einer Konversation, die selten auftreten und somit Ausnahmen in der Konversation darstellen. Diese Edge Cases erstellt man unter anderem innerhalb der Conversational Map bzw. den Conversation Flows. Das Gegenstück zu Edge Cases stellen der Happy Paths dar. Hierbei beschreibt man die erwartungsgemäßen Ausgänge einer Konversation, die am häufigsten vom Nutzer genommen werden.
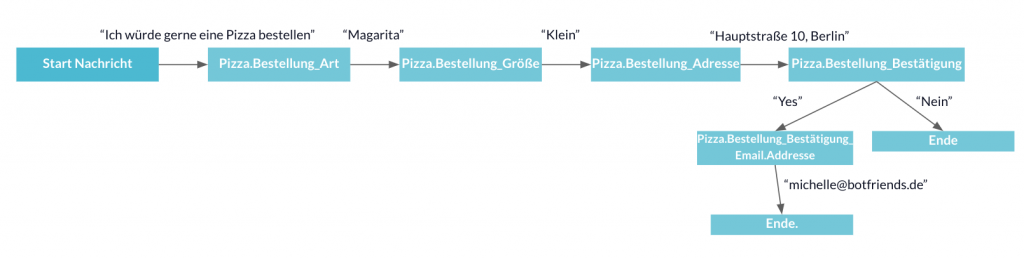
Beispiel für den Happy Path am Use Case "Pizza bestellen"
An diesem Beispiel wird dargestellt wie eine "glückliche" Konversation zwischen User und Chatbot aussehen kann bei einer Pizza Bestellung. Alle Informationen, welche der Nutzer dem Chatbot mitgibt können verarbeitet werden und es entstehen keine Missverständnisse.
Beispiel für den Edge Case am Use Case "Pizza bestellen"
An diesem Beispiel erkennt man, dass es allerdings auch großes Fehlerpotenzial geben kann, wenn der User Antworten sendet, welche der Chatbot nicht verarbeiten kann. In der unteren Grafik wird gezeigt, dass der User eine Adresse eingibt, die außerhalb von Deutschland ist. In diesem Fall kann keine Lieferung stattfinden. Solche Edge Cases sollte man im Vorhinein bedenken und in der Conversational Map abbilden. Man sollte sich fragen, wie in solchen Situationen mit dem User umgegangen wird. Zum Beispiel informiert man den Nutzer, dass man nur innerhalb von Deutschland liefert oder man gibt ihm die Möglichkeit die Adresse erneut einzugeben im Falle eines Missverständnisses.

> Zurück zum BOTwiki