
 AI Agent ROI Calculator
AI Agent ROI Calculator Free training: Chatbot crash course
Free training: Chatbot crash course Whitepaper: The acceptance of chatbots
Whitepaper: The acceptance of chatbotsTo optimize latency in voicebots, companies should rely on streaming outputs, prompt caching, and a model-agnostic architecture. The combination of specialized AI models and efficient multi-agent orchestration enables human-like response times in real time.
Optimizing Latency in Voicebots: The Key to Excellent Customer Service
Imagine you call a hotline and ask a simple question. There’s a three- to five-second silence before the digital assistant responds. In a natural conversation, that pause feels like an eternity. It leads customers to believe the connection has been lost, or they start speaking just as the bot is about to respond.
At Voicebots and AI agents , the time delay between user input and the system’s response—known as latency—is the deciding factor between technological brilliance and total frustration.
While a short wait time is acceptable in chat, phone calls require real-time interaction. High latency inevitably leads to reduced user satisfaction and a loss of efficiency in the service. In this article, you’ll learn how to optimize latency in voicebotsto enable smooth, human-like dialogues.
What does latency mean in the context of voicebots, and why is it critical?
In AI systems, latency refers to the time interval between receiving an input and generating the corresponding output. In the context of voicebots , this process is particularly complex, as it involves not only semantic processing in the background but also the conversion of speech to text and back.
Low latency is crucial for the acceptance of AI applications. In real-time scenarios, even milliseconds can make the difference between a natural conversation and a choppy, laborious interaction. For businesses, optimized latency is a direct driver of higher first-call resolution (FCR) rates and improved process automation. A delay is often perceived as a sign of the system’s lack of competence, which increases bounce rates.
The Components of Latency: Where Do Delays Occur in Voicebots?
To optimize optimize latency in voicebots, you need to understand the individual steps that make up the total delay:
- Speech-to-Text (STT): The customer’s spoken words must be transcribed in real time. The chosen provider (e.g., Azure or Google) plays a major role here.
- Processing & Knowledge Retrieval (NLU/LLM): The system analyzes the intent and searches for relevant information. Larger, more complex language models (LLMs) typically require more time for these calculations than specialized, smaller models.
- Generating the response: This is where the response text is generated. The number of output tokens directly affects the duration.
- Text-to-Speech (TTS): The generated text is converted back into a natural-sounding voice.
Smart Latency Optimization for Voicebots: More Than Just Speed
There are several strategies you can use to significantly reducethe response time of your chatbots and voicebots:
- Streaming Responses: Instead of waiting for the LLM to generate the entire sentence, the text is "streamed." The TTS service begins speech output even while the AI is still formulating the end of the sentence.
- Prompt caching & efficient context management: Caching frequently used instructions (prompts) reduces the computational load.
- Model Agnosticism & Specialization: Using smaller, optimized models for simple tasks and high-end models (such as GPT-4o or Claude 3.5 Sonnet) only for complex logical inferences strikes a balance between speed and quality.
- Reducing the number of output tokens: Precise system prompts instructthe AI agent to keep its responses brief and concise, which significantly reduces generation time.
BOTfriends' Approach to Maximizing Voicebot Performance
To deliver high-end technology without the typical "enterprise overhead," BOTfriends relies on a high-performance architecture that eliminates technical bottlenecks and puts the user experience first. Our approach to optimizing latency for voicebots includes:
Use of PTU models

For our customers, we rely on Provisioned Throughput Units (PTUs) instead of traditional PAYGO (Pay-As-You-Go) instances. The key advantage: While standard solutions require you to share the cloud provider’s hardware resources with a multitude of other companies, PTUs guarantee exclusively reserved computing capacity.
The Difference: Public Lanes vs. Exclusive Lanes
To illustrate the technological advantage, the AI infrastructure can be compared to a highway:
- Standard Instances (PAYGO): This corresponds to the public lane. During peak hours (when there is a high volume of global requests), data traffic slows down. As a result, your AI responds slowly, and customers have to wait for answers.
- PTU Models: This is your private, exclusive lane. Regardless of overall traffic volume, your lane remains clear and reserved for you. Your AI agent therefore always delivers results at the fastest possible speed and without any fluctuations in performance.
By permanently allocating capacity, we eliminate dependence on third-party usage. You benefit from predictable latency and stable, high bandwidth.
Smart Load Balancing
Our intelligent load-balancing approach distributes traffic evenly across all available models. This helps us avoid hotspots and overloads that could cause delays.
In-memory databases
For data processing, we use extremely fast in-memory databases such as Redis. This keeps access times to a minimum and noticeably speeds up response times.
Incremental output via WebSockets
Thanks to WebSockets, requests don’t have to be fully completed before the user receives a response. This allows the bot to send a message even while an API integration is still running in the background. Feedback is immediate, making the interaction much smoother.
Minimizing perceived latency
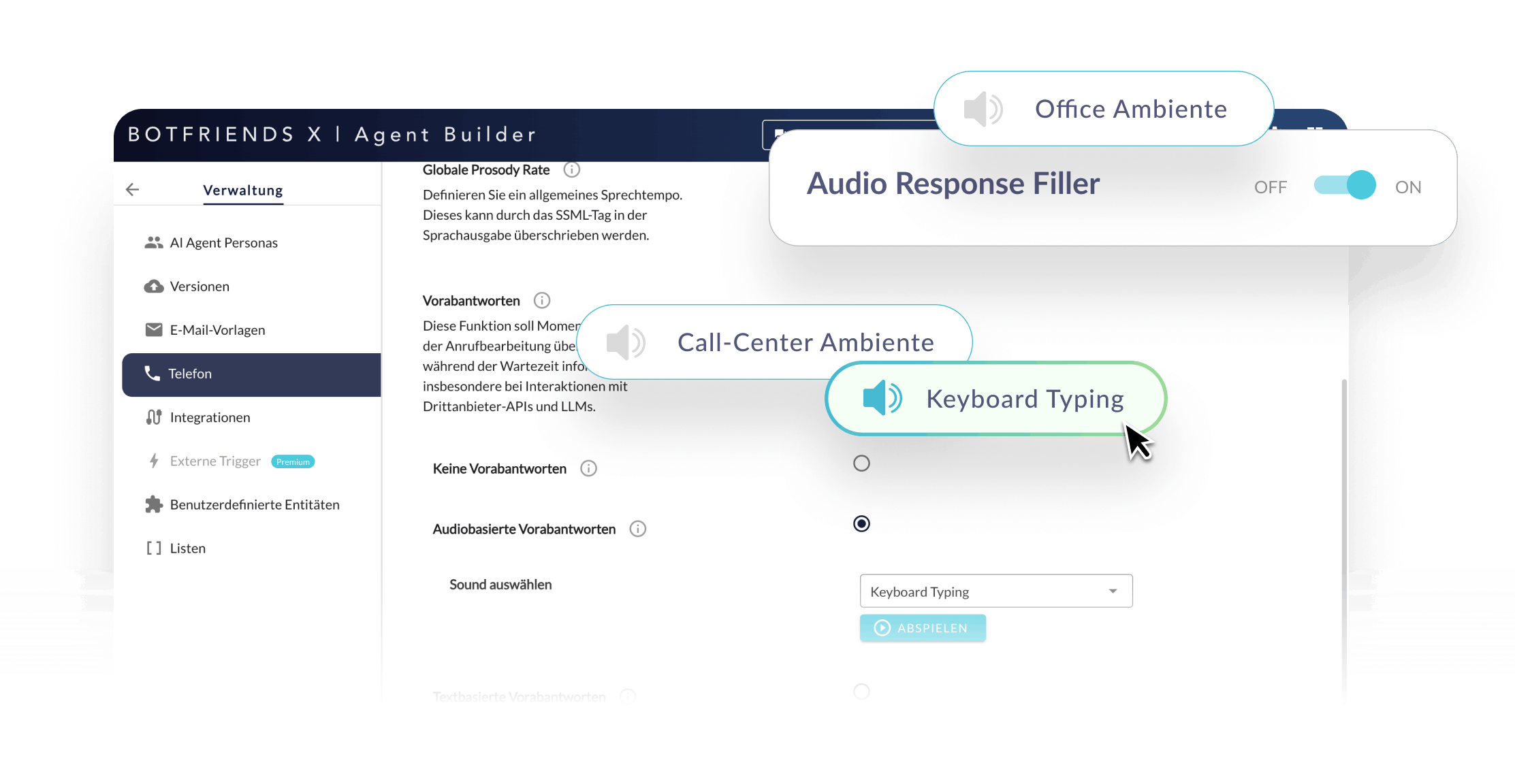
Since user perception is crucial, we strategically use fillers. Brief remarks such as “Just a moment, let me check…” or subtle background sounds like keyboard clicks or office ambient noise bridge technical processing times and create a natural conversational flow.
Optimizing Latency in Voicebots: Your Path to Excellent Customer Service
Optimizing latency is not a one-time project, but an ongoing process involving monitoring and technical fine-tuning. Companies that invest in this area secure a competitive advantage through technological sovereignty —they remain independent of individual providers while offering their customers the best possible experience.
With BOTfriends by your side, you get not just a platform, but a partner who guides you toward independence through Guided Sovereignty. We ensure that your AI agents not only respond intelligently, but also do so at a pace that mirrors natural human conversation.
Ready for voicebots that don’t keep your customers waiting?
Schedule a no-obligation consultation and learn more about our AI platform for voice, chat, and email automation.